
 DevOps-监控】生产环境是如何设计一个全方位的监控系统 (保姆级)
DevOps-监控】生产环境是如何设计一个全方位的监控系统 (保姆级)
转载请注明:
作者:TodoCoder
出处: https://www.todocoder.com/posts/011.html 公众号转载微信搜: TodoCoder
Docker监控系列文章
【DevOps-监控】Docker可视化监控原理及采集方案
【DevOps-监控】生产环境是如何落地一套全方位的监控系统的 (保姆级 4000字带你分析)
【DevOps-监控】生产环境是如何设计一个全方位的监控系统 (保姆级)
大家好,我是Coder哥,上一篇我们聊了 大厂监控落地保姆教程(Docker版),是基于cAdvisor + Prometheus + Grafana + Node-exporter 搭建的一套针对容器和节点资源的可视化监控系统,这套系统也是当前主流的云监控平台的解决方案,当然了监控平台搭建起来后还有一个非常重要的功能,那就是预警,没有预警,监控的意义就不大了。那么今天我们就来聊一下预警。
本篇文章会从预警机制到常见的预警场景开始,从理论到实践手把手教你搭建一套完善的预警系统,绝对的干货,相信会帮到你,如果觉得以后可能用的到别忘了收藏。
我们从以下的内容出发
- 线上环境的预警场景有哪些?
- 整个监控平台的预警机制到底是什么?
- 预警的搭建保姆教程。
线上环境的预警场景有哪些?
咱们上一篇文章大厂监控落地保姆教程(Docker版)搭建了一套监控系统,实现了对Node的CPU、内存、磁盘、网络等方面的指标的监控,为了能及时的发现并处理问题,就需要系统给我们发个预警通知,通知的方式可以是WebHook、邮件、飞书、企业微信等。那么我们在线上的具体使用场景都有哪些呢?
- 比如CPU 10分钟内持续90%以上,我们可能认为是有问题的,需要排查一下。
- 磁盘,或者内存超过 80% 需要提醒相应人员来扩容或者清理。
- 发预警消息的频率如何控制,比如:1分钟检测一次,如果发出预警,隔多久如果没处理需要再次发送?
- 如果同一时刻不同维度的多消息都产生了,能否合并成一条消息统一发送过来?
- 大量重复告警,要怎么办?
- 等等。。。。
上面这些都是我们在真实使用中需要解决的问题,并不是只简单的搭建起来就行了,里面的控制机制我们也需要了解。接下来我们看看这套预警系统是怎么解决这些问题的?
预警机制到底是什么?
一、Prometheus告警规则
在介绍预警特性之前我们先来看一下预警的流程,上篇文章里面已经画了整体的监控到预警的流程及组件,可以看一下如下图:
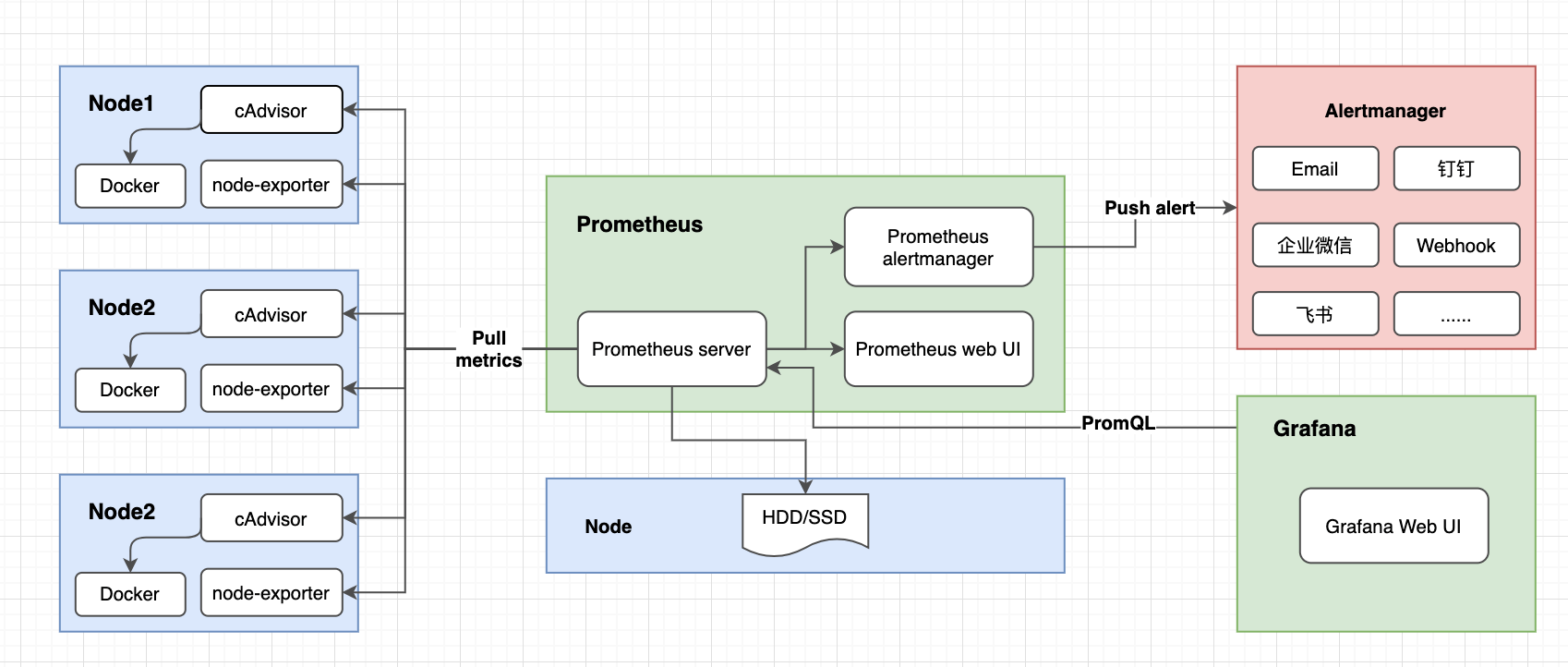
从图中我们可以看到,Prometheus定期从组件 cAdvisor、node-exporter中获取节点及容器的资源信息,持久化信息到磁盘,然后这些数据通过Grafana展示到Web页面上,除了这些,Prometheus还会分析这些数据,当这些数据满足一定的条件,就会发送消息给Alertmanager, Alertmanager则会处理并格式化这些消息,然后发送通知给你。注意: 这里的分析数据就是prometheus根据一组告警规则来判断是否满足这个规则,如果满足就发通知给AlertManager组件。
告警规则: 预警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警。
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些都是通过yaml文件来统一管理的。
上面我们只是通过Prometheus根据告警规则选出满足预警的数据,这只是初步的筛选,这些数据都会给到AlertManager。AlertMananger会对数据进一步处理,比如大量消息过来的时候,会对消息进行去重,同时对消息进行分组并且路由通知到正确的地方(邮件、企业微信等...)。所以我们说Prometheus处理只是第一步,那么接下来我们看看第二步,第二步是由AlertManager处理的。
二、AlertManager告警处理
AlertMananger是Prometheus监控系统中的一个独立组件,负责接受并处理来自Prometheus 的告警信息。作为告警信息的第二步处理,他是通过什么样的机制来处理信息的呢?我们先来简单了解几个概念:
- 去重(deduplicating): 比如高可用 AlertManager 部署多个实例的时候,同一个告警同时发到所有的高可用节点,会根据 hash 进行去重
- 分组(grouping): 比如可以根据
AlertName,Instance,Job等任意 label 对海量告警进行分组. 典型情况就是, 突然好多 Pod 都发出了AlertName: InstanceDown的 Alerts, 那么可以直接根据AlertName进行分组后发送, 这样用户只会收到一封xxx 个 Pods InstanceDown的告警邮件,能大大减少告警接收人员的收件量。 - 静默/屏蔽(silencing): 静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
- 抑制(inhibition):抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。常用场景,高级别的告警触发(firing)后,低级别的告警就不用发了。比如:磁盘空间的
critical级别告警已经触发(空间使用超过 90%), 这时候warning级别的告警(空间使用超过 80%)就被抑制。 - 路由(routing): 将告警跟进一定的过滤条件发送到指定的 receiver. 如: 满足
job=db的告警路由给 DBA; 满足team=todocoder的告警路由给 todocoder 的邮件组... - 接收器(receiver): 具体的通知渠道 + 收件人。如: 邮件通知渠道+邮箱; 等等;
详细的流程如下:
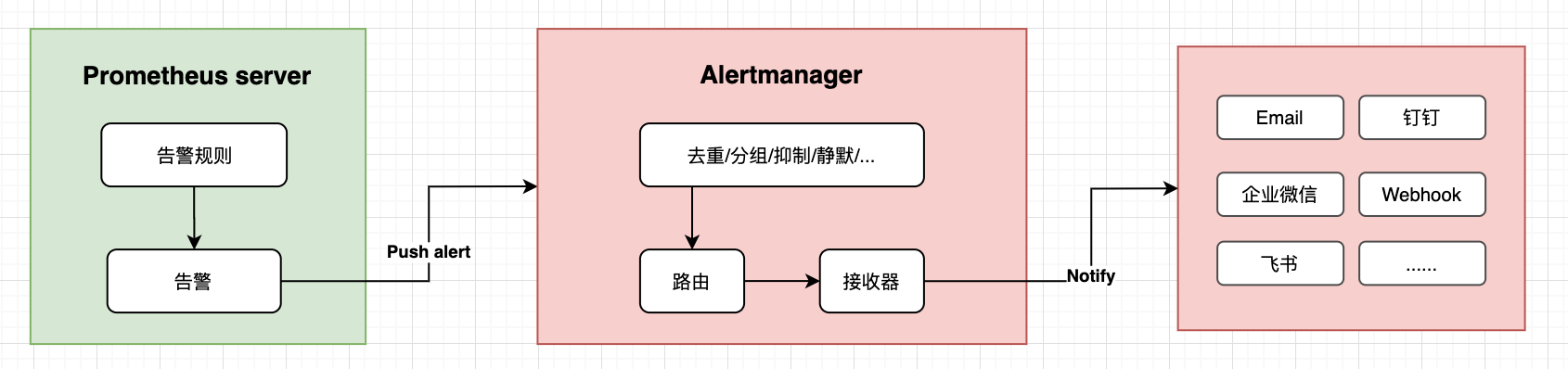
那么接下来我们来看一下具体是怎么操作的:
预警的搭建保姆教程(邮箱)
一、环境信息
| 软件 | 版本 | 说明 |
|---|---|---|
| Ubuntu | 22.04.1 | IP: 192.168.111.37 |
| Docker | 20.10.21 | |
| Prometheus | bitnami/prometheus:2.45.0 | 开放端口: 8093 |
| node-exporter | bitnami/node-exporter:1.6.1 | 开放端口: 8092 |
| cAdvisor | todocoder/cadvisor:v0.47.2 | 开放端口: 8091 |
| Grafana | grafana/grafana:9.5.6 | 开放端口: 3001 |
| Alertmanager | bitnami/alertmanager:0.26.0 | 开放端口: 8094 |
整体的环境信息如上,本文只安装预警部分Alertmanager,监控部分安装可以查看: 大厂监控落地保姆教程(Docker版)
二、安装预警系统
从上面的流程我们可以知道,预警有两部分,第一部分是Prometheus的告警规则,第二部分才是Alertmanager的配置。
第一步:Prometheus告警规则配置
上一篇文章我们已安装了Prometheus,相关信息如下:
存储数据目录: /data/prometheus/data
配置目录: /data/prometheus/conf
- 修改配置文件:
vi /data/prometheus/conf/prometheus.yml
global:
scrape_interval: 30s # Set the scrape interval to every 30 seconds. Default is every 1 minute.
evaluation_interval: 30s # Evaluate rules every 30 seconds. The default is every 1 minute.
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.111.37:8094
rule_files:
# 这个路径不用动,因为在启动prometheus的时候已经挂载到 /data/prometheus/conf 下了
# -v=/data/prometheus/conf:/opt/bitnami/prometheus/conf
- /opt/bitnami/prometheus/conf/rules/*.yml
scrape_configs:
- job_name: "todocoder-prometheus"
static_configs:
- targets: ["192.168.111.37:8093"]
- job_name: "todocoder-cadvisor"
static_configs:
- targets: ["192.168.111.37:8091"]
- job_name: "todocoder-node37" # 这个是监控node
static_configs:
- targets: ['192.168.111.37:8092']
- job_name: "todocoder-alertmanager"
static_configs:
- targets: ['192.168.111.37:8094']
相较于之前启动时候的配置增加了如下的部分:
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.111.37:8094
rule_files:
# 这个路径不用动,因为在启动prometheus的时候已经挂载到 /data/prometheus/conf 下了
# -v=/data/prometheus/conf:/opt/bitnami/prometheus/conf
- /opt/bitnami/prometheus/conf/rules/*.yml
注意:这里的规则路径不用动,因为在启动prometheus的时候已经挂载到 /data/prometheus/conf 下了,具体可查看上一篇监控搭建文章
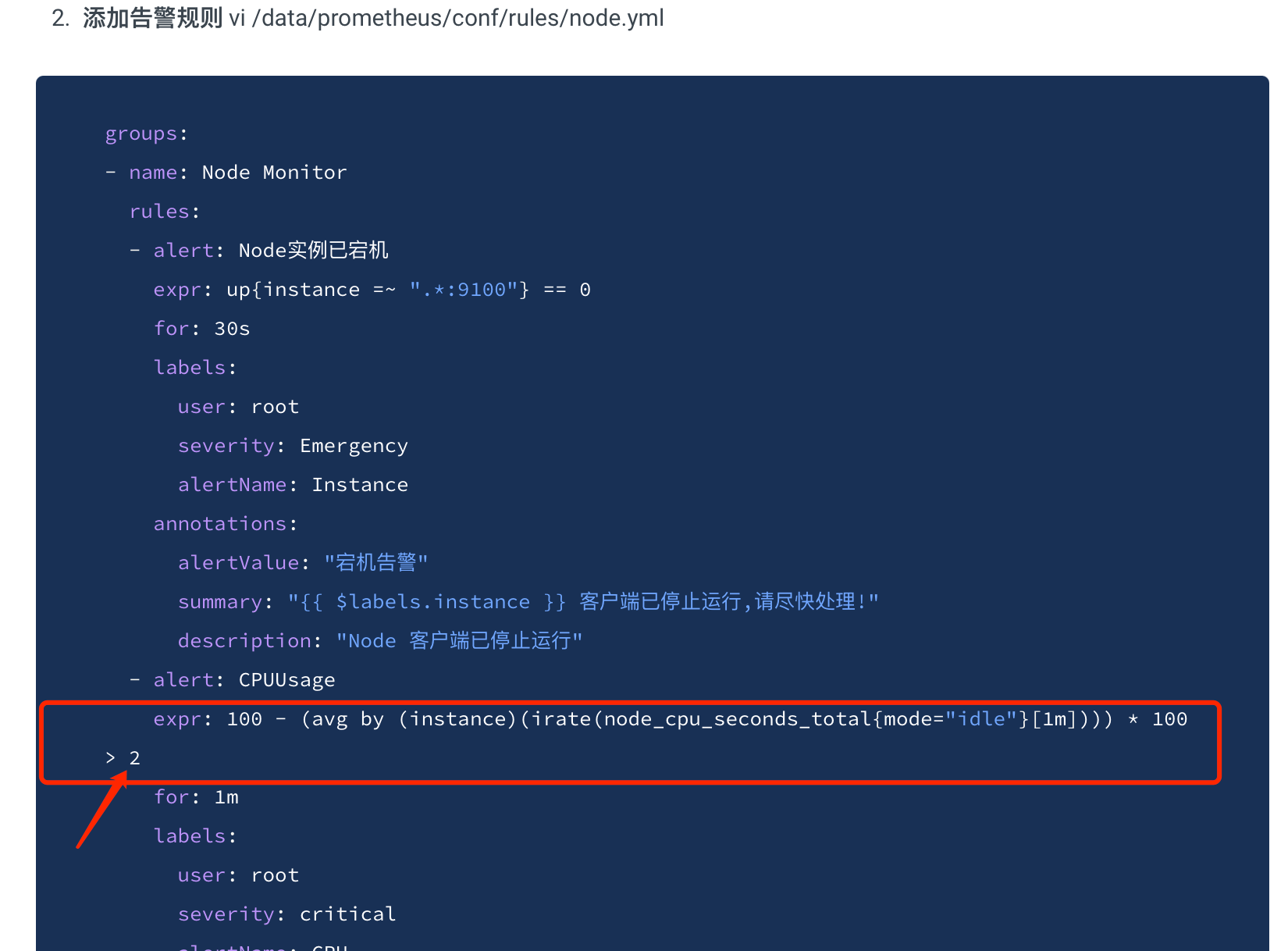
- 添加告警规则 vi /data/prometheus/conf/rules/node.yml
groups:
- name: Node Monitor
rules:
- alert: Node实例已宕机
expr: up{instance =~ ".*:9100"} == 0
for: 30s
labels:
user: root
severity: Emergency
alertName: Instance
annotations:
alertValue: "宕机告警"
summary: "{{ $labels.instance }} 客户端已停止运行,请尽快处理!"
description: "Node 客户端已停止运行"
- alert: CPUUsage
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]))) * 100 > 2
for: 1m
labels:
user: root
severity: critical
alertName: CPU
annotations:
alertValue: "90%"
summary: "{{ $labels.instance }} CPU使用率超过90%"
description: "{{ $labels.instance }} CPU使用率超过90% 已经持续1m"
- alert: MEMUsage
expr: ((node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100) > 90
for: 1m
labels:
user: root
severity: fire
alertName: Memory
annotations:
alertValue: "90%"
summary: "{{ $labels.instance }} 内存使用率超过90%"
description: "{{ $labels.instance }} 内存使用率超过90% 已经持续1m"
- alert: DISKUsage
expr: avg by (device)((node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100) > 90
for: 1m
labels:
user: root
severity: warning
alertName: DISK
annotations:
alertValue: "90%"
summary: "{{ $labels.instance }} 磁盘使用率超过90%"
description: "{{ $labels.instance }} 磁盘使用率超过90% 已经持续5m"
这里添加了四种场景的告警规则: 节点宕机、CPU使用>90%、内存使用>90%、磁盘使用>90%
具体可根据你公司的实际情况来配置
上面的标签(labels)可以用来分组用,注解(annotations)可以在邮件模板中取到对应的值
- 添加完这两个配置后,重启已经安装好的prometheus
docker restart todocoder-prometheus
如果没有安装可参考上篇文章或者如下的安装运行命令:
docker run \
-d=true \
-p=8093:9090 \
--name=todocoder-prometheus \
-v=/data/prometheus/conf:/opt/bitnami/prometheus/conf \
-v=/data/prometheus/data:/opt/bitnami/prometheus/data \
bitnami/prometheus:2.45.0 \
--web.enable-lifecycle --web.enable-admin-api \
--config.file=/opt/bitnami/prometheus/conf/prometheus.yml \
--storage.tsdb.path=/opt/bitnami/prometheus/data
启动后可以打开web页面:http://192.168.111.37:8093/alerts?search= 注意ip换成你自己的
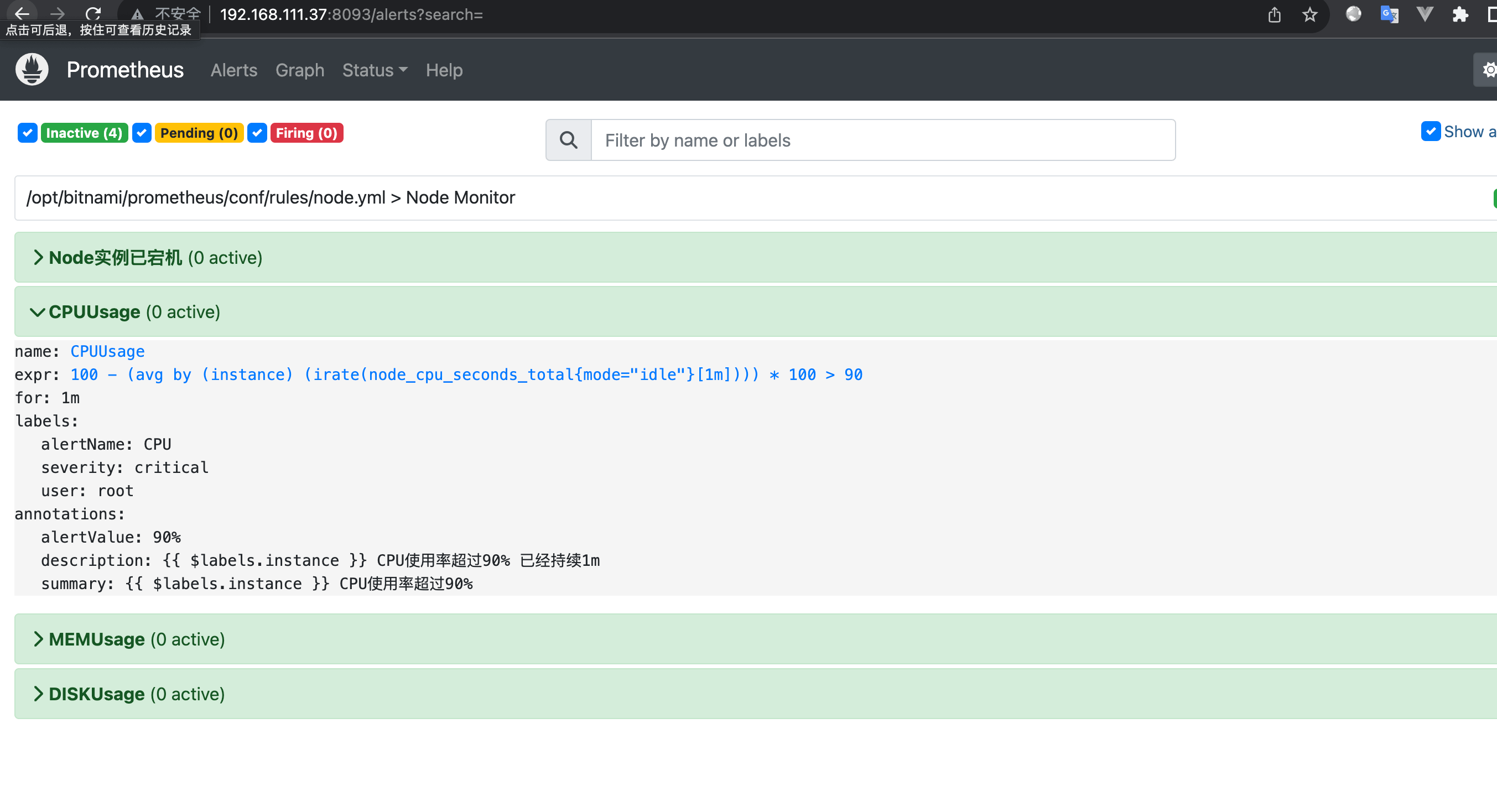
可以看到,预警规则已经在prometheus中了,现在我们测一下CPU使用率,因为90%的使用率比较难达到,我们可以修改一下规则 比如说改为 CPU > 1% 就预警:
vi /data/prometheus/conf/rules/node.yml
修改完后重启,查看一下预警的情况:
docker restart todocoder-prometheus
查看预警:http://192.168.111.37:8093/alerts?search=
可以看到预警信息已经触发如下:
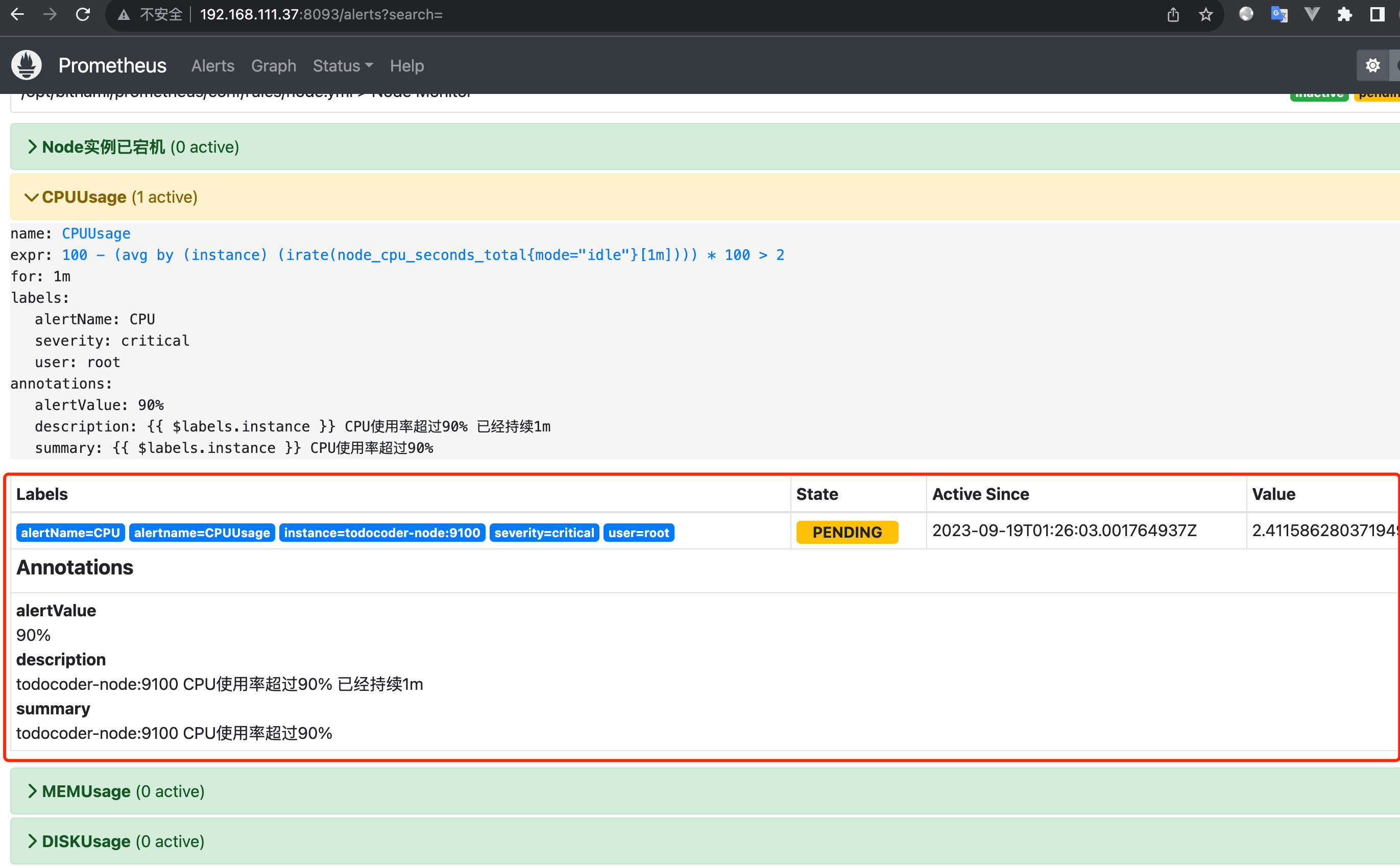
到这一步,我们Prometheus的告警规则以及触发流程已经都捋顺了,接下来看第二步:
第二步:安装 Alertmanager
- 创建 alertmanager.yml
vi /data/prometheus/conf/alertmanager.yml
global:
# 每2分钟检查一次是否恢复
resolve_timeout: 2m
# 邮箱smtp服务器 smtp.163.com:25 smtp.qq.com:465
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: 'xxx@qq.com'
# 邮箱名称
smtp_auth_username: 'xxx@qq.com'
# 邮箱授权码
smtp_auth_password: 'xxxx'
smtp_require_tls: false
# 自定义通知模板
templates:
- '/etc/alertmanager/template/email.tmpl'
# route用来设置报警的分发策略
route:
# 采用哪个标签来作为分组依据
group_by: ['instance']
# 组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出
group_wait: 10s
group_interval: 30s # 同一分组内告警下次发送需等待时间(按照分组标签决定)
# 单个告警重复发送时间
repeat_interval: 1h
# 设置默认接收人
receiver: 'email'
routes:
- receiver: 'email'
continue: true
group_wait: 10s
receivers:
- name: 'email'
email_configs:
- to: 'xxx@163.com'
html: '{{ template "email.message" . }}'
headers: { Subject: "TodoCoder [Warning] 报警邮件" }
send_resolved: true
注意点:
smtp_smarthost: 是用于发送邮件的邮箱的SMTP服务器地址+端口;
163/qq邮箱smtp服务器地址: smtp.163.com:25 smtp.qq.com:465
smtp_auth_password: 是发送邮箱的授权码而不是登录密码;
qq邮箱授权码获取:设置 -> 账号 -> 开启
POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务 163邮箱授权码获取: 设置 -> POP3/SMTP/IMAP -> 开启服务
templates: 指出邮件的模板路径;
smtp_require_tls:不设置的话默认为true,当为true时会有starttls错误,为了简单这里设置为false;
receivers下html: 指出邮件内容模板名,这里模板名为
email.message需要和邮件模板中的define一样,在模板路径中的某个文件中定义。headers:为邮件标题
- 定义邮箱模板
vi /data/prometheus/conf/template/email.tmpl
{{ define "email.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range $i, $alert :=.Alerts }}
<b>告警主题:</b> {{ $alert.Labels.alertname }} <br>
<b>告警类型:</b> {{ $alert.Labels.alertName }} <br>
<b>告警状态:</b> {{ .Status }} <br>
<b>告警级别:</b> {{ $alert.Labels.severity }} <br>
<b>告警应用:</b> {{ $alert.Annotations.summary }} <br>
<b>故障主机:</b> {{ $alert.Labels.instance }} <br>
<b>触发阀值:</b> {{ $alert.Annotations.alertValue }} <br>
<b>告警详情:</b> {{ $alert.Annotations.description }} <br>
<b>触发时间:</b> {{ $alert.StartsAt }} <br>
<center>=============================</center><br>
{{ end }}
{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
<b>告警主题:</b> {{ $alert.Labels.alertname }} <br>
<b>告警类型:</b> {{ .Labels.alertName }} <br>
<b>告警状态:</b> {{ .Status }} <br>
<b>告警级别:</b> {{ .Labels.severity }} <br>
<b>告警应用:</b> {{ .Annotations.summary }} <br>
<b>故障主机:</b> {{ .Labels.instance }} <br>
<b>触发阀值:</b> {{ .Annotations.alertValue }} <br>
<b>告警详情:</b> {{ .Annotations.description }} <br>
<b>触发时间:</b> {{ .StartsAt }} <br>
<b>恢复时间:</b> {{ .EndsAt }} <br>
<center>=============================</center><br>
{{ end }}
{{ end -}}
{{ end -}}
- 部署Alertmanager
docker run \
-d=true \
-p=8094:9093 \
--name=todocoder-alertmanager \
-v=/data/prometheus/conf/alertmanager.yml:/etc/alertmanager/config.yml \
-v=/data/prometheus/conf/template:/etc/alertmanager/template \
--network=monitor \
bitnami/alertmanager:0.26.0
http://192.168.111.37:8094/#/alerts 如下图:
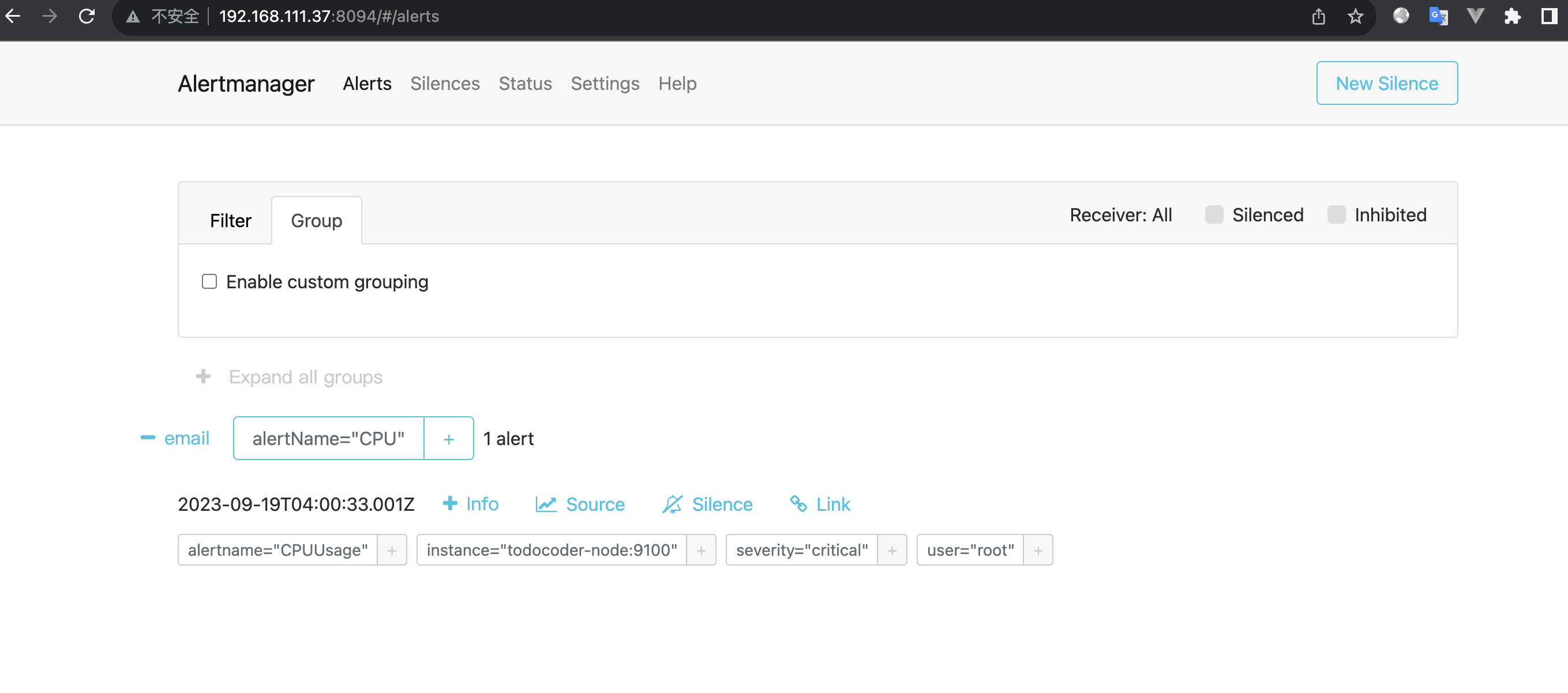
- 检测邮件结果
在上面Prometheus 预警规则配置中 我们配置了测试阈值 CPU使用率 > 2% 触发预警值,触发邮件如下:

我们还可以测试节点宕机和恢复,执行如下命令:
宕机:
docker stop todocoder-node
查看http://192.168.111.37:8093/alerts?search=
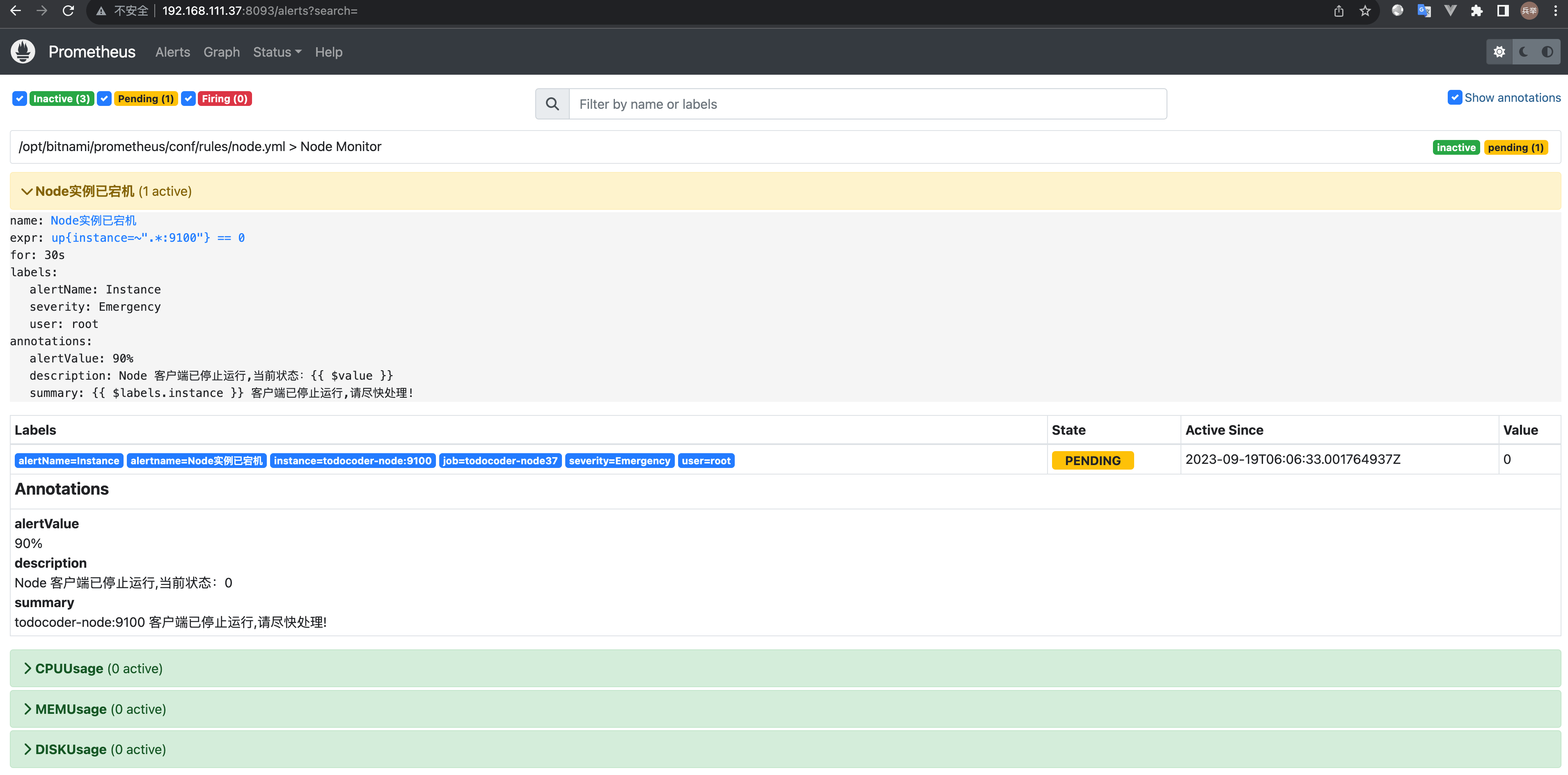
查看邮件

节点恢复
docker start todocoder-node
查看http://192.168.111.37:8093/alerts?search=
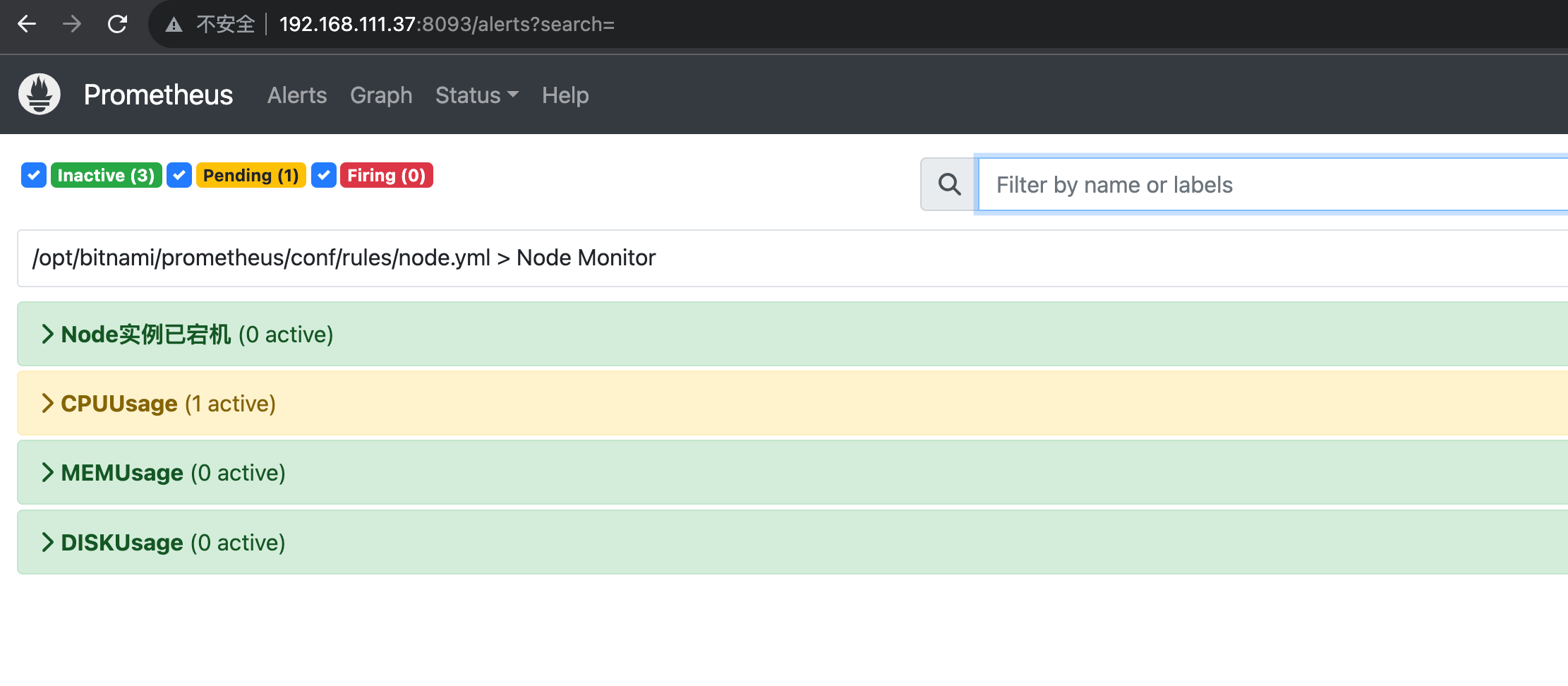
查看邮件

可以看到恢复的时间,
注意:
上面有时区的问题,如果线上使用可以注意再告警的时候手动+8:00 ,
或者基于当前的镜像把线上主机的时区挂载进去,本篇文章都是基于官方的镜像
基于监控和预警的docker-compose.yml , 及一键部署脚本还在整理中如下:
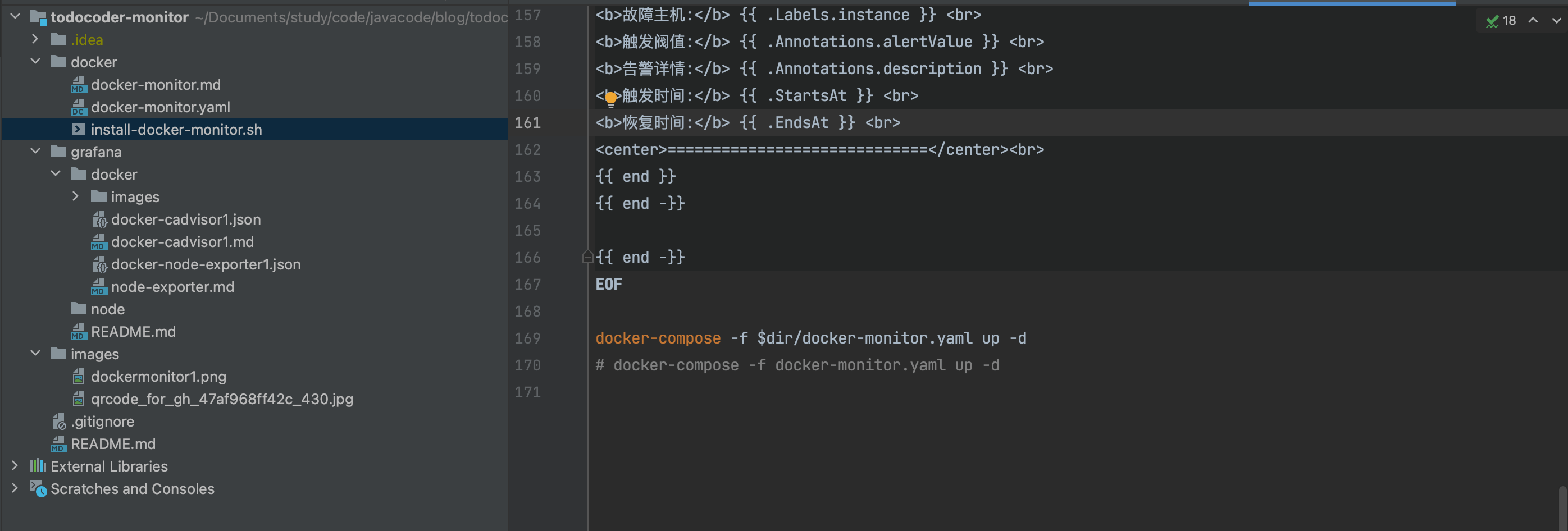
如有需要,可以私我,VX:todocodercom,或者微信工号搜: TodoCoder 直接发消息跟我要就行,后面会更新上来
结语
本文主要是填坑,在上一篇文章大厂监控落地保姆教程(Docker版)中由于篇幅有限,只介绍了整个监控系统,还差个预警,终于有空把坑填上了,感谢各位能看到这里,觉得文章有用的话记得关注一下,别忘了点赞收藏哦。
感谢各位能看到这里,觉得文章有用的话记得关注一下,别忘了点赞收藏哦,最后打个小广告
微信工号搜: TodoCoder
会不定时分享 Java,Go,Docker,k8s等 技术文章,公号无广告,无推荐,纯分享
微信搜索关注公众号 TodoCoder 回复 201 可获取全套源码还有基于Docker系统的监控源码和模板
