
【并发容器】为什么Map桶中超过8个才转为红黑树?
大家好,我是Coder哥,在技术日新月异的今天,真正应该花费时间学习的是那些不变的编程思想,上一章 【并发容器】ConcurrentHashMap 在 Java7 和 8 有何不同?】 聊了ConcurrentHashMap 在 Java7 和 8 有何不同,我们本章聊一下为什么Map桶中超过8个才转为红黑树?我们从以下几个方面谈谈。
- HashMap 的数据结构与拉链法。
- 链表转红黑树的原因
- 为什么阈值设为 8?
- 极端情况:不均匀的哈希分布。
- 这么设计的意义是什么?
- 总结
HashMap 的数据结构与拉链法
HashMap 的核心是通过 哈希函数 将 key-value 对分配到固定数量的桶(也称为槽位)中。当多个 key 的哈希值映射到同一个桶时,会形成一个链表(如图所示):
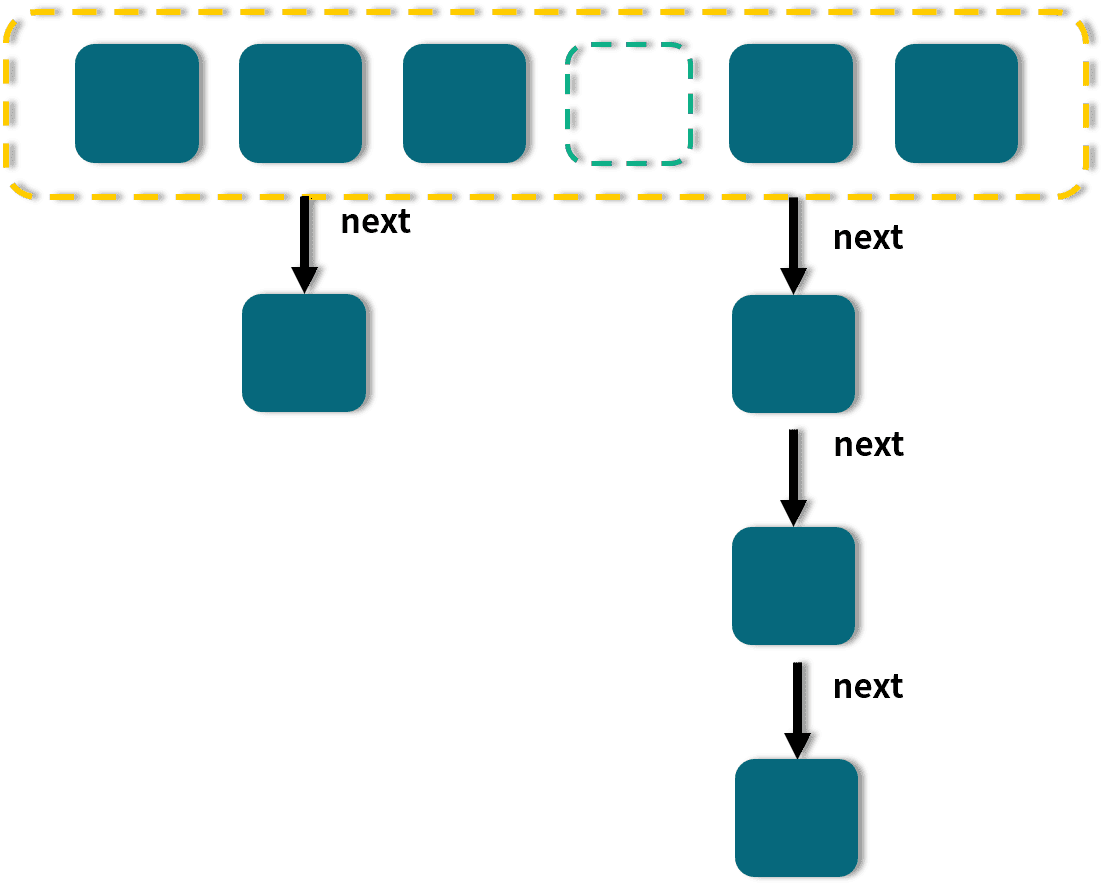
在图中可以看到:
- 第 4 个桶是空的;
- 第 1、3、6 个桶只有一个元素;
- 第 2 和第 5 个桶采用“拉链法”,包含多个元素。
当链表长度 大于等于 8 且容量达到 MIN_TREEIFY_CAPACITY(默认 64)时,链表会被转换为红黑树。反之,当红黑树的节点数减少到 6 或更少时,会还原为链表。那么为什么链表会转成红黑树呢?
链表转红黑树的原因
我们知道链表的查询效率为 O(n),其中 n 是链表的长度。而红黑树是一种自平衡二叉搜索树,其查询效率为 O(log n)。当链表较短时,O(n) 和 O(log n) 的性能差异不明显。但当链表变长时,查询性能会显著下降。为了提高性能,HashMap 会在链表长度达到一定阈值(默认 8)后,将其转换为红黑树。
这种转换机制的实现基于性能与空间的权衡。正如 JDK 源码中的注释所解释:
Because TreeNodes are about twice the size of regular nodes,use them only when bins
contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become
too small (due removal or resizing) they are converted back to plain bins.
这段话意思是:单个 TreeNode 的空间开销大约是普通节点的两倍,因此只有在桶中的节点足够多时,才会进行树化操作,而是否足够多就是由 TREEIFY_THRESHOLD 的值决定的。而当桶中节点数由于移除或者 resize 变少后,又会变回普通的链表的形式,以便节省空间。那么这里的阈值为什么设计成8呢?
为什么阈值设为 8?
要理解为何默认阈值为 8,需要结合概率分布和实际使用场景。JDK 源码中对此有详细说明:
In usages with well-distributed user hashCodes, tree bins are rarely used.
Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson
distribution (http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter
of about 0.5 on average for the default resizing threshold of 0.75, although with
a large variance because of resizing granularity. Ignoring variance, the expected
occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The first values are:
在理想情况下,如果哈希函数分布均匀,桶中节点数量会遵循 泊松分布。以下是链表长度 k 的概率分布:
| 链表长度 (k) | 概率 |
|---|---|
| 0 | 0.60653066 |
| 1 | 0.30326533 |
| 2 | 0.07581633 |
| 3 | 0.01263606 |
| 4 | 0.00157952 |
| 5 | 0.00015795 |
| 6 | 0.00001316 |
| 7 | 0.00000094 |
| 8 | 0.00000006 |
当链表长度达到 8 时,其概率仅为 0.00000006,即小于千万分之一。在实际场景中,链表长度极少达到 8。因此,设置 8 作为阈值既能兼顾性能,又能避免不必要的空间开销。既然概率这么低为啥还要加这个功能?
极端情况:不均匀的哈希分布
尽管在理想情况下链表长度很难超过 8,但在以下场景中会导致链表过长:
- 自定义的哈希函数设计不当;
- 多个 key 的哈希值发生大量冲突。
例如,以下代码中所有对象的 hashCode 都为 1,这会导致所有 key 被分配到同一个桶:
@Override
public int hashCode() {
return 1;
}
让我们来看下面这段代码:
public class HashMapDemo {
public static void main(String[] args) {
HashMap map = new HashMap<HashMapDemo,Integer>(1);
for (int i = 0; i < 1000; i++) {
HashMapDemo hashMapDemo1 = new HashMapDemo();
map.put(hashMapDemo1, null);
}
System.out.println("运行结束");
}
@Override
public int hashCode() {
return 1;
}
}
运行这段代码时,HashMap 内部的链表会不断增长。当链表长度超过 8 且满足其他条件时,会自动转换为红黑树,如下所示:
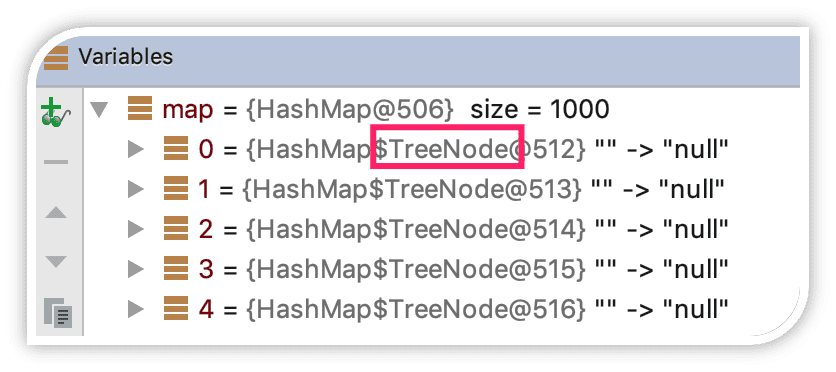
这么设计的意义是什么?
链表长度超过 8 转为红黑树,更多是为了应对极端情况,确保查询效率不会因为哈希冲突而大幅下降。在正常情况下,良好的哈希函数设计能将链表长度控制在较短范围内,避免树化操作的空间开销。
如果在实际开发中发现 HashMap 内部出现了红黑树结构,可能说明:
- 哈希函数的设计存在问题;
- 数据分布不均匀导致了大量冲突。
优化 hashCode 和 equals 方法,是减少冲突、提升性能的关键。
总结
链表长度超过 8 转为红黑树,是 HashMap 的重要优化策略。它通过平衡时间复杂度和空间占用,在性能和资源之间找到了最佳折中。了解这一设计可以帮助我们在实际开发中规避潜在问题,写出更高效、健壮的代码。
书籍推荐:
《计算机内功修炼系列》:https://www.todocoder.com/pdf/jichu/001001.html
《Java编程思想》 :https://www.todocoder.com/pdf/java/002002.html
《Java并发编程实战》 :https://www.todocoder.com/pdf/java/002004.html