
【锁思想】深入探究JVM锁优化思想:自适应自旋锁、锁消除、锁粗化、偏向锁等。
大家好,我是Coder哥,在技术日新月异的今天,真正应该花费时间学习的是那些不变的编程思想,我们来接着上一篇文章来聊一下锁,今天这篇文章是 【锁思想系列】 的最后一篇文章了,我们不聊锁的宏观类别层面的思想,因为前几篇基本把所有重要的锁思想聊的差不多了,比如:悲观/乐观、公平/非公平、读写锁、自旋锁等等,今天我们从JVM层面来聊一下,JVM是怎么从系统层面来优化锁的?
提到JVM的锁,相信你应该能想到是哪个锁了,对就是synchronized,在 Java 1.5 以及之前,synchronized 的性能比较低,灵活度也不高,虽然他是系统级别的锁,但是也不是很受待见,但是到了 Java 1.6 以后,发生了变化,因为 虚拟机底层对 synchronized 做了很多优化,比如自适应自旋、锁消除、锁粗化、偏向锁、轻量级锁等,所以后期的 Java 版本里的 synchronized 的性能并不比 Lock 差了,可谓是应用了所有锁优化的思想。话不多说我们开聊:
自适应的自旋锁
之前我们详细的分析过自旋和CAS【锁思想】Java开发者必读:深入理解自旋锁与CAS的关系及应用 ,我们知道自旋是锁在获取方式上的一种优化,“自旋”就是不释放 CPU,一直循环尝试获取锁,但是自旋也有缺点,可以看一下如下代码:
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
可以看到代码中使用一个 do-while 循环来一直尝试修改 long 的值。虽然可以避免上下文切换的开销,但是缺点也很明显,如果自旋时间过长,会持续占用CPU,浪费了 CPU 资源。所以官方帮我们想了个法子:自适应自旋锁。
于是在 JDK 1.6 中引入了自适应的自旋锁来解决长时间自旋的问题,它的出现使得自旋操作变得聪明起来。
那么何为自适应呢?
自适应自旋是一种改进的自旋锁策略,它不再固定自旋的时间和次数,而是根据多种因素来决定。这些因素包括最近自旋尝试的成功率、失败率以及当前锁的拥有者的状态。自旋的持续时间是可变的,使得自旋锁变得更加智能。举个例子,如果最近尝试自旋获取某个锁成功了,那么下一次可能会继续使用自旋,并且允许自旋的时间更长;但是如果最近自旋获取某个锁失败了,那么可能会跳过自旋的过程,以减少无用的自旋,提高效率。
锁消除
第二个优化点是锁消除,我们先来看一下如下的代码:
public class LockEliminate {
public static String getString(String sb1, String sb2) {
StringBuffer sb = new StringBuffer();
sb.append(sb1);
sb.append(sb2);
return sb.toString();
}
public static void main(String[] args) {
long tsStart = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
getString("LockEliminate ", "Dliminate");
}
System.out.println("共耗时:" + (System.currentTimeMillis() - tsStart) + " ms");
}
}
// StringBuffer 源码
@Override
public synchronized StringBuffer append(Object obj) {
toStringCache = null;
super.append(String.valueOf(obj));
return this;
}
在这段代码中,我们看到StringBuffer.append() 函数上加了个 synchronized 锁,并且在main 函数中有一个for循环来调用StringBuffer.append() 函数,假如我们调用了10000000次,而且这是在同一个线程中也是线程安全的。试想一下,这个程序会进行10000000次锁的获取吗,如果是你的话你要怎么优化它?
如果是我的话首先,肯定会先判断一下这个代码块是否在其他线程中是否有引用,也就是是否存在竞态条件,如果不存在的话,就认为是安全的,其次,如果只是本线程可以访问,自然是线程安全的,也就无需加锁。
没错,编译器也是按照这样的思想优化的,那么问题来了,编译器是怎么判断函数getString()中的变量是否安全呢,这个就是利用逃逸分析的技术,简单来讲逃逸分析就是,分析函数中的数据是否逃逸到函数作用域外部(这里不展开讲),JVM是默认开启的(需要在server模式下),也可以通过参数来控制:
-server -XX:+DoEscapeAnalysis
第一步满足了,那么第二步就是编译器会根据逃逸分析的结果来判断代码是否是只在单个线程里面执行,如果是的话,编译器会把加锁的过程给消除掉,这个就是所谓的锁消除,锁消除的控制JVM是默认开启的,也可以通过如下的参数来控制:
-server -XX:+EliminateLocks
我们来看一下上面代码实际运行的结果:
不加锁消除的运行时间:
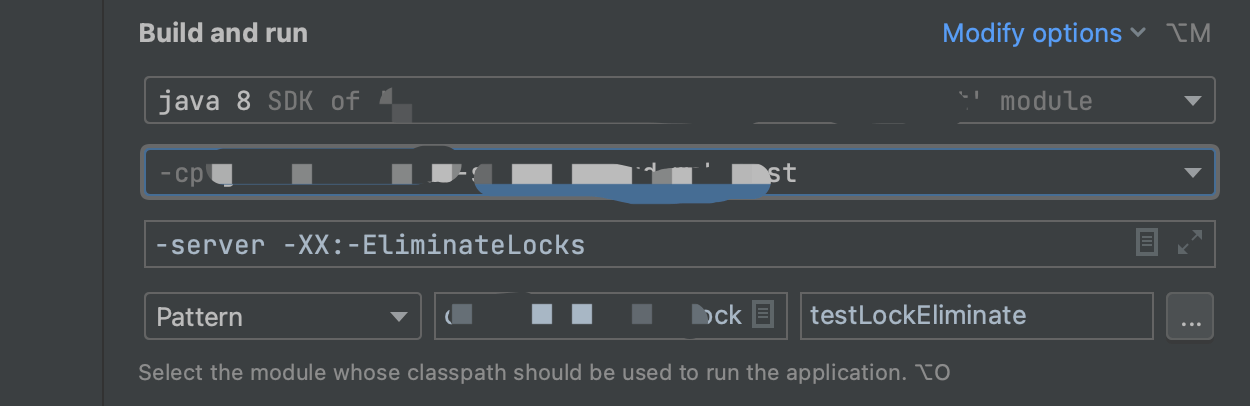
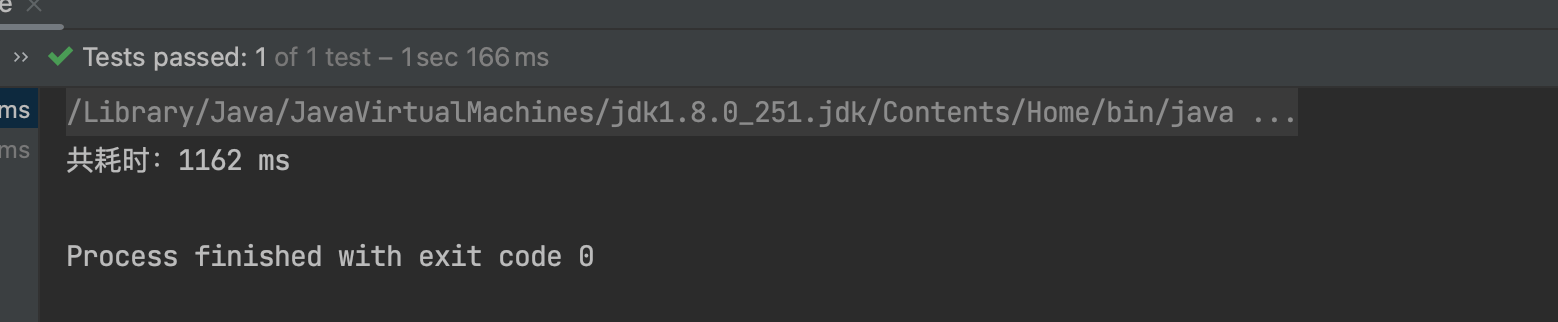
不加锁消除耗时 1162ms
加锁消除的运行时间
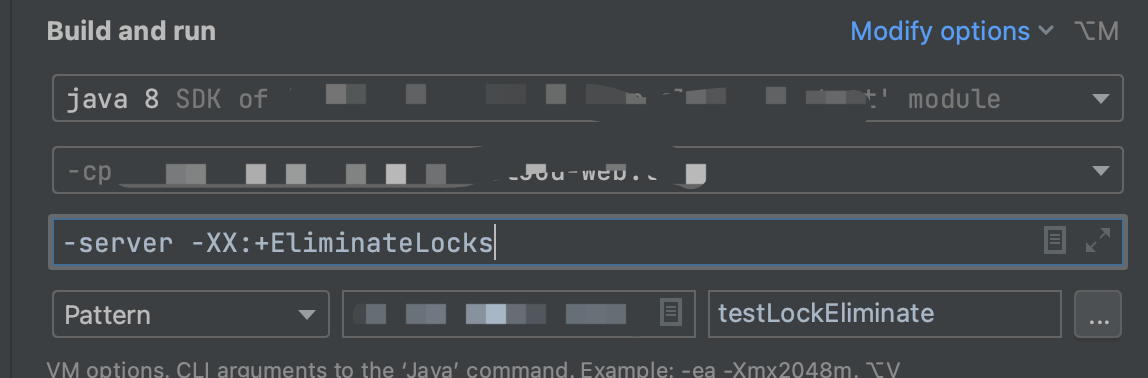
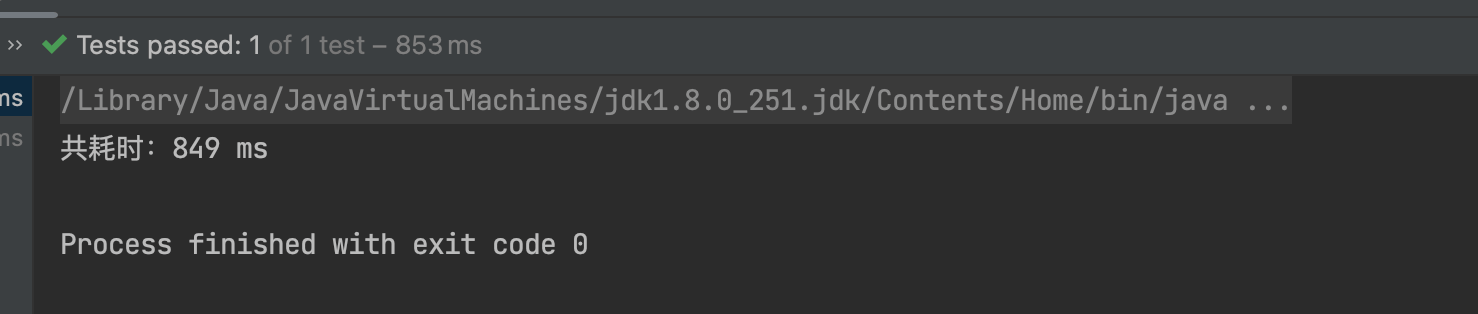
加锁消除耗时 849ms
从上面结果看,锁消除的效果还是很明显的。
其实大多数情况下,StringBuffer只会在一个线程内被使用,如果编译器能确定这个 StringBuffer 对象只会在一个线程内被使用,就代表肯定是线程安全的,那么我们的编译器便会做出优化,把对应的 synchronized 给消除,省去加锁和解锁的操作,以便增加整体的效率。
锁粗化
上面我们了解了锁消除,那么我们来聊下一个场景,锁粗化
例如下面这段代码所示,如果我们释放了锁,然后什么都没做,又重新获取锁
public void lockCoarsening() {
synchronized (this) {
//do something1
}
synchronized (this) {
//do something2
}
synchronized (this) {
//do something3
}
}
可以看到上面的代码,连续加锁多次,从代码逻辑上来讲,是完全没有必要的,其实这段代码只在开始加一次锁然后在最后解锁就可以了。这样就可以把中间这些无意义的解锁和加锁的过程消除,相当于是把几个 synchronized 块合并为一个较大的同步块。这样做的好处在于在线程执行这些代码时,就无须频繁申请与释放锁了,这样就减少了性能开销。
但是还有一种场景,如果在循环中,比如如下代码是否会进行锁粗化呢?
int sum = 0;
for (int i = 0; i < 1000; i++) {
synchronized (this) {
sum += i;
}
}
理论上来说是可以的,因为这样确实也可以提高性能,但是有个缺点是这样会将锁的粒度增加太多,线程在执行循环时将会长时间独占锁,导致其他线程长时间无法获得锁。所以,JVM不会对整个循环做锁的粗化处理的。这里有个循环展开的概念,先给结果:JVM会依赖于循环展开进行锁粗化,而不是对整个循环进行粗化,这样既保证了性能也不至于独占锁时间太久。
我们来简单介绍一下循环展开是怎么进行锁粗化的:
比如上面的代码,循环了1000次,并且每一个循环体内,除了必须的加法计算代码以外,同时存在2条循环条件判断指令。这么算的话,上面的代码(忽略掉加锁解锁) 循环加判断一共是1000 * (2 + 3) = 5000次指令,那么如果循环如果按步长5展开,编译器会优化成如下的代码:
int sum = 0;
for (int i = 0; i < 200; i += 5) {
synchronized (this) {
sum += i;
sum += i + 1;
sum += i + 2;
sum += i + 3;
sum += i + 4;
}
}
这样我们再来算一下CPU指令多少个: 200 * (2 + 5 * 3) = 3400 次CPU指令,可以看到进行循环展开后,可以优化CPU操作指令的操作次数,那么锁粗化也会依赖于循环展开,只在展开内部进行粗化,不会对整个循环进行粗化,这样既保证了性能也不至于独占锁时间太久。
说明: 上面的 2是循环条件的两次判断指令,3是
sum += i的CPU操作指令个数(不理解可以自行查阅 i++的原理)
偏向锁/轻量级锁/重量级锁
下面我们来看一下三种特殊的synchronized锁状态:偏向锁、轻量级锁和重量级锁。这些锁的状态是通过对象头中的mark word来标识的。
- 偏向锁
偏向锁的设计理念基于一个场景:如果一个锁从未经历过竞争,那么实际上没有必要进行完全的锁定操作,只需进行标记即可。在对象初始化后,如果没有任何线程尝试获取其锁,那么该对象就是可偏向的。当第一个线程尝试获取该对象的锁时,系统会记录下这个线程。如果后续尝试获取锁的线程是这个偏向锁的持有者,那么它可以直接获取锁,这样的开销非常小。
- 轻量级锁
JVM的开发者注意到,在许多情况下,synchronized代码块是被多个线程交替执行的,也就是说,并不存在实际的锁竞争,或者只有短时间的锁竞争。在这种情况下,可以通过CAS(Compare and Swap)操作来解决,而无需使用重量级锁。轻量级锁是在原本为偏向锁的情况下,当另一个线程尝试访问时,表明存在锁竞争,此时偏向锁会升级为轻量级锁。线程会通过自旋的方式尝试获取锁,而不会进入阻塞状态。
- 重量级锁
重量级锁是通过操作系统的同步机制实现的,因此其开销相对较大。当多个线程之间存在实际的锁竞争,且锁竞争时间较长时,偏向锁和轻量级锁无法满足需求,此时锁会升级为重量级锁。重量级锁会使得尝试获取但未能成功的线程进入阻塞状态。
最后,我们看下锁的升级路径,如图所示,锁的升级路径从无锁到偏向锁,再到轻量级锁,最后到重量级锁。偏向锁具有最佳性能,避免了CAS操作。轻量级锁利用自旋和CAS操作避免了重量级锁带来的线程阻塞和唤醒,性能居中。而重量级锁会将无法获取锁的线程阻塞,性能最差。

JVM 默认会优先使用偏向锁,如果有必要的话才逐步升级,这大幅提高了锁的性能。
总结
锁优化是在多线程编程中提高性能和减少竞争的关键技术之一。本文中,我们将讨论几种常见的锁优化思想:自适应的自旋锁、锁消除、锁粗化以及偏向锁、轻量级锁和重量级锁。
- 自适应的自旋锁: 自旋锁是一种在多线程环境下等待锁释放的技术。传统的自旋锁会一直忙等待,消耗大量的CPU资源。而自适应的自旋锁则根据前一次在同一个锁上的自旋时间来决定是否继续自旋。如果前一次自旋时间较长,那么下一次就会更倾向于阻塞线程而不是自旋,从而减少CPU的消耗。
- 锁消除: 在某些情况下,编译器可以通过静态分析判断出一段代码中不可能存在竞争的情况,因此可以将对应的锁消除掉。这样可以减少不必要的锁开销,提高程序的执行效率。
- 锁粗化: 锁粗化是将多个连续的细粒度锁合并成一个粗粒度锁的优化技术。当一段代码中存在多个连续的加锁和解锁操作时,如果这些操作都是针对同一个对象的,那么可以将它们合并成一个大的锁范围,从而减少加锁和解锁的次数,提高程序的性能。
- 偏向锁、轻量级锁和重量级锁: 这三种锁是针对Java中的synchronized关键字的不同状态而设计的。偏向锁是为了解决无竞争情况下的性能问题,轻量级锁是为了在短时间内的竞争中提高性能,而重量级锁则是为了处理长时间竞争的情况。这些锁的设计都是为了在不同的竞争场景下提供最佳的性能和资源利用率。
通过了解和应用这些锁优化思想,我们可以在多线程编程中提高性能、减少竞争,并提升程序的执行效率。
书籍推荐:
《计算机内功修炼系列》:https://www.todocoder.com/pdf/jichu/001001.html
《Java编程思想》 :https://www.todocoder.com/pdf/java/002002.html
《Java并发编程实战》 :https://www.todocoder.com/pdf/java/002004.html